

 Linux providing a better gaming performance than Microsoft Windows is no longer of any kind of anomaly
Linux providing a better gaming performance than Microsoft Windows is no longer of any kind of anomaly 
AMD Radeon RX 9070 XT / Linux kernel 6.14 / Mesa 25 benchmarked on Arch Linux (Steam OS bases on BTW) vs. Windows 11.

youtu.be- YouTubeAuf YouTube findest du die angesagtesten Videos und Tracks. Außerdem kannst du eigene Inhalte hochladen und mit Freunden oder gleich der ganzen Welt teilen.





 Hacker News
Hacker News 






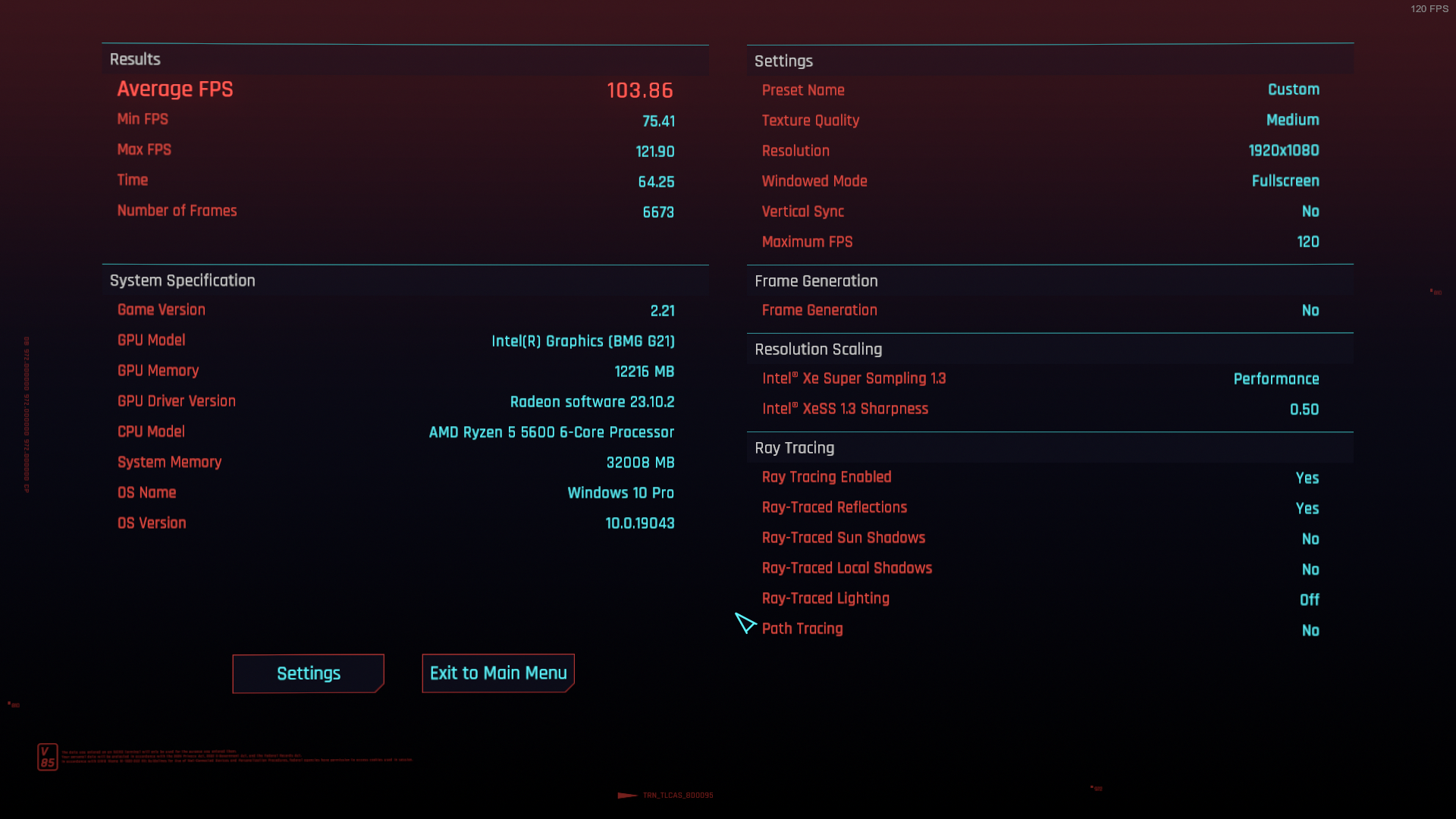



 Di. 25.03.25
Di. 25.03.25 12:30-13:30 (s.t.)
12:30-13:30 (s.t.)


 Assassin's Creed Shadows im Performance Check auf GeForce NOW Ultimate
Assassin's Creed Shadows im Performance Check auf GeForce NOW Ultimate 




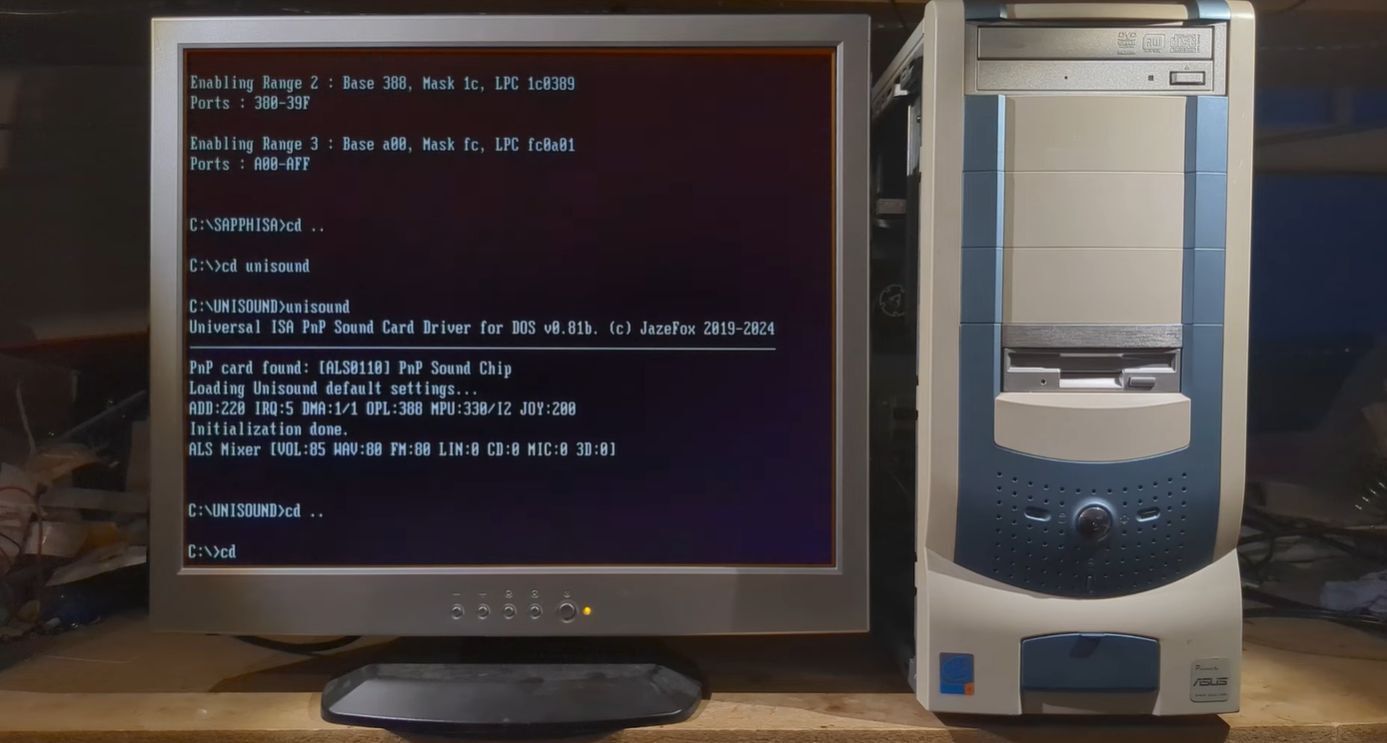




 Le Acer Nitro N50-600, un PC gaming sous-estimé ?
Le Acer Nitro N50-600, un PC gaming sous-estimé ? 



")





