
Is there some nice web frontend for #duckdb that lets users do faceted searches and supports permalinks?
Frühere Suchanfragen
Suchoptionen

#duckdb
5 Beiträge5 Beteiligte0 Beiträge heute

Bonus Drop #82 (2025-04-12): Quick Hits
QH: Lit Lit; QH: Beyond Quacking; QH: Granary
This hit kind of hard Friday night (the Trump administration deliberately dropped that nugget after the news cycle), so y’all are getting barely edited notes for a bonus Drop this weekend.
I know I sound like some insane person, but if you are a reader who is in the U.S., it would not be unwise to stock up on shelf-stable/non-perishable item before the 20th. If I’m wrong, the worst-case scenario is that you have extra stuff for a while. If I’m right…
TL;DR
(This is an AI-generated summary of today’s Drop using Ollama + llama 3.2 and a custom prompt.)
For the record, I’ve not changed anything, and it just started to do this “summary of” stuff o_O.
- Summary of Lit web components (https://lit.dev) – A concise overview of Lit’s core advantages and features, including native browser support, encapsulation via Shadow DOM, and TypeScript-first design.
- Summary of FlockMTL paper (FlockMTL) – An introduction to FlockMTL, a DuckDB extension integrating LLMs and RAG capabilities into SQL workflows, targeting knowledge-intensive analytical applications.
- Summary of Granary library (https://granary.io/) – A universal translator for social web data, enabling interoperability between native APIs, scraped HTML, and standardized formats like ActivityStreams v1/v2, microformats2, Atom, RSS, and JSON Feed.
QH: Lit Lit
Photo by Lgh_9 on Pexels.comLongtime readers of the Drop know I  Lit webcomponents. This past week, I came across — quite literally — the absolute best post describing what they are, why they rock, and how best to use them.
Lit webcomponents. This past week, I came across — quite literally — the absolute best post describing what they are, why they rock, and how best to use them.
In “The Case for Web Components with Lit”, Philipp Kunz covers all these topics concisely, but thorough enough to both make convincing case to use Lit, but also to teach an old dog (like me) some new and spiffy tricks when it comes to using Lit in the most optimal way possible.
- Core Web Component advantages: native browser support, encapsulation via Shadow DOM, framework interoperability, scalability
- Lit library features: reactive properties, declarative templates, performance optimizations, TypeScript-first design
- TypeScript integration patterns: type-safe properties/events, interface-driven development, enhanced tooling support
- Component development techniques:
- Slot-based composition
- Reactive controllers for state management
- Lifecycle hooks and DOM querying
- CSS-in-JS styling with Lit’s
csstag
- Testing strategies using modern web test runners
- Performance optimization methods:
- Template caching
- Efficient update detection
- Lit’s
repeatdirective
- Framework interoperability examples for React/Vue
- Real-world implementation patterns:
- Design system components
- Micro-frontend architectures
- TypeScript best practices:
- Strong event/property typing
- Generic component patterns
- Custom event definitions
- Companion tooling showcase (dees-wcctools)
- Resource references for deeper exploration
QH: Beyond Quacking
Photo by Pixabay on Pexels.comI read “Beyond Quacking: Deep Integration of Language Models and RAG into DuckDB” earlier in April, and it’s a perfect item for this weekend’s “Quick Hits” edition since I don’t have a DuckDB-focused edition on the planning calendar for a bit.
The paper features FlockMTL — a DuckDB extension integrating LLMs and RAG capabilities directly into SQL workflows, targeting knowledge-intensive analytical applications. It introduces novel schema objects (MODEL, PROMPT), semantic functions, and optimizations to simplify complex data pipelines combining structured/unstructured data analysis.
These are the notes on FlockMTL core features ripped from my Joplin page on it:
MODEL & PROMPT are first-class resources letting us modify global LLM/ML configs without modifying our actual queries:
CREATE GLOBAL MODEL('model-relevance-check', 'gpt-4o-mini', 'openai');CREATE PROMPT('joins-prompt', 'is related to join algos given abstract'); FlockMTL comes with new semantic DDB functions:
- Scalar (
llm_filter,llm_complete_json) - Aggregate (
llm_rerank,llm_first/last) - Hybrid search fusion (RRF, CombMNZ, etc.)
FlockMTL introduces several optimizations to enhance LLM-integrated SQL workflows, focusing on efficiency and usability. Here’s a technical breakdown of the key mechanisms:
“Batching” dynamically groups input tuples into optimal batch sizes based on LLM context windows, achieving 7× speedup for chat completions and 48× for embeddings. The system automatically reduces batch sizes by 10% upon context overflow errors and handles edge cases where individual tuples exceed context limits by returning NULL.
“Meta-Prompting” implements structured prompt templates that combine user instructions with:
- Formatting rules
- Output expectations
- Serialized tabular inputs
“Execution Plan Controls” extends DuckDB’s query planner with:
- Batch size visualization/overrides
- Serialization format selection (XML/JSON/Markdown)
- Meta-prompt inspection tools
Example Workflow
WITH relevant_papers AS ( SELECT * FROM research_papers WHERE llm_filter(params, prompt, {title, abstract}))SELECT llm_complete_json(params, prompt, {content}) AS insights, llm_rerank(params, prompt, content) AS rankingsFROM relevant_papers Supports cloud (OpenAI/Azure) and local (Ollama) LLMs.
If you have an Apple Silicon Mac or another system with a compatible GPU, this is a nice way to experiment with RAG in a SQL context.
QH: Granary
Photo by Juan Martin Lopez on Pexels.comEvery social media platform uses a different “content object” format, despite all of them (pretty much) having the same overall structure.
Granary (GH) is a spiffy library and REST API designed to fetch and convert social data across various platforms and formats. It acts as a (sort of) universal translator for social web data, enabling interoperability between native APIs, scraped HTML, and standardized formats like ActivityStreams v1/v2, microformats2, Atom, RSS, and JSON Feed. The framework emphasizes open protocols while supporting major platforms including Twitter, Mastodon, Bluesky/AT Protocol, GitHub, and Instagram.
The tool provides two primary interfaces:
- A Python library (
pip install granary) for programmatic access - A REST API available at granary.io for HTTP-based interactions. Both methods handle OAuth authentication and return data wrapped in ActivityStreams 1.0 JSON with OpenSocial envelope formatting by default. The API supports multiple output formats including ActivityPub-compatible JSON, Atom feeds, and microformats2 HTML.
Recent updates (v8.1 as of March 2025) added enhanced Bluesky integration including hashtag facets, improved content truncation for non-space-delimited languages, and NIP-27 support for Nostr. The project emphasizes privacy – no user data is stored, only transformed in transit.
Tis a super-niche solution, but is also a nice codebase to peruse if you want to get familiar with the various socmed platform data formats.
FIN
Remember, you can follow and interact with the full text of The Daily Drop’s free posts on:
 Mastodon via
Mastodon via @dailydrop.hrbrmstr.dev@dailydrop.hrbrmstr.dev Bluesky via
Bluesky via https://bsky.app/profile/dailydrop.hrbrmstr.dev.web.brid.gy





Just released duckfetch v0.4.0 which allows you to manage DuckDB installation on Linux/Windows and macOS
https://github.com/PMassicotte/duckfetch/releases/tag/v0.4.0


 DevelopersIO
DevelopersIO DatabricksでS3に外部テーブルとして作成したDeltaテーブルにローカル環境のPythonからアクセスしてみた
https://dev.classmethod.jp/articles/databricks-s3-delta-python/

DatabricksでS3に外部テーブルとして作成したDeltaテーブルにローカル環境のPythonからアクセスしてみた | DevelopersIODatabricksでS3に外部テーブルとして作成したDeltaテーブルにローカル環境のPythonからアクセスしてみた | DevelopersIO
Antwortete im Thread


My browser WASM’t prepared for this. Using DuckDB, Apache Arrow and Web Workers in real life | by Motif Analytics | Feb, 2025 | Medium

Medium · My browser WASM’t prepared for this. Using DuckDB, Apache Arrow and Web Workers in real life

Danke, dass ich gestern Teil des #DigitalCraftsDay2025 sein durfte.
Hat mir Mega Spaß gemacht, über #DuckDB zu reden und einen kleinen Einblick zu geben, was damit alles an #Datenanalyse, #Datenmanagement und #AdvancedSQL möglich ist. 



#TIL about a #CLI #Ruby tool to do #dataviz in the #terminal: Youplot -- https://github.com/red-data-tools/YouPlot
Found it while reading the #duckdb documentation (https://duckdb.org/docs/stable/guides/data_viewers/youplot)


Thanks to a live Data Camp session I found out that there are helper aggregate functions for linear regression in SQL in DuckDB
e.g.
regr_slope()
regr_intercept()
https://duckdb.org/docs/stable/sql/functions/aggregates.html
DuckDBAggregate Functions




howdy, #hachyderm!
over the last week or so, we've been preparing to move hachy's #DNS zones from #AWS route 53 to bunny DNS.
since this could be a pretty scary thing -- going from one geo-DNS provider to another -- we want to make sure *before* we move that records are resolving in a reasonable way across the globe.
to help us to do this, we've started a small, lightweight tool that we can deploy to a provider like bunny's magic containers to quickly get DNS resolution info from multiple geographic regions quickly. we then write this data to a backend S3 bucket, at which point we can use a tool like #duckdb to analyze the results and find records we need to tweak to improve performance. all *before* we make the change.
then, after we've flipped the switch and while DNS is propagating --  -- we can watch in real-time as different servers begin flipping over to the new provider.
-- we can watch in real-time as different servers begin flipping over to the new provider.
we named the tool hachyboop and it's available publicly --> https://github.com/hachyderm/hachyboop
please keep in mind that it's early in the booper's life, and there's a lot we can do, including cleaning up my hacky code. 
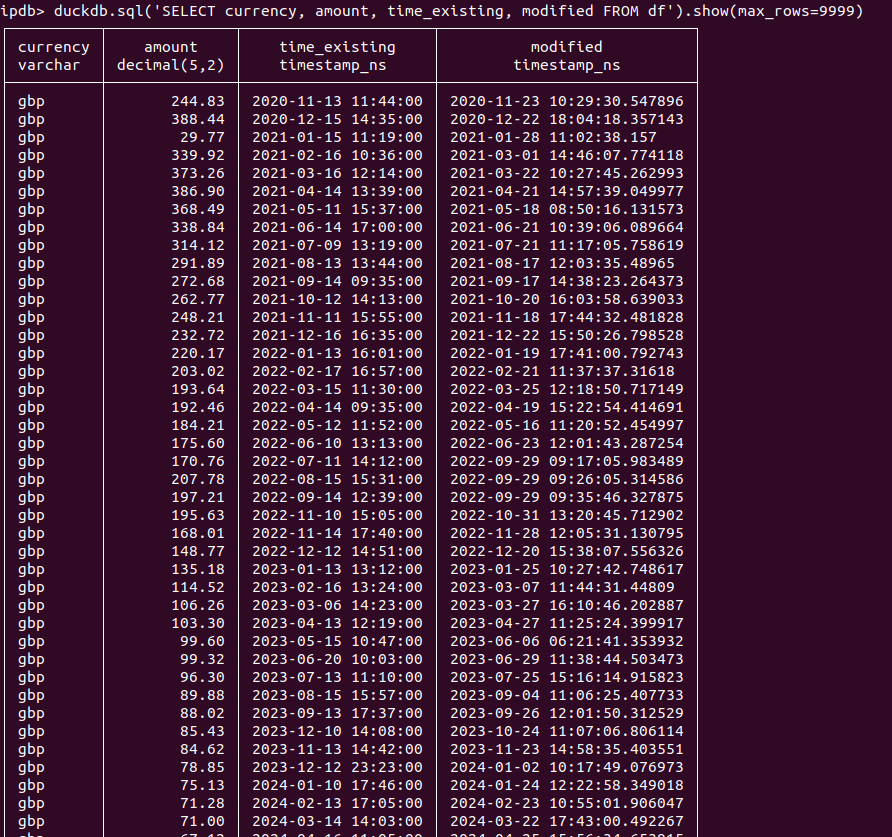
attached is an example of a quick run across 17 regions for a few minutes. the data is spread across multiple files but duckdb makes it quite easy for us to query everything like it's one table.

Antwortete im Thread



Fortgeführter Thread

Thank you to #Kone & Mai and Tor Nessling Foundations for supporting this work. A quantitative work like this would not be possible without a robust suite of FOSS tools. My thanks to the maintainers of #QGIS, #pandas, #geopandas, #duckdb, #dask, #statsmodels, #jupyter and many more!


 Jelte Fennema-Nio (@jeltef) returns to #PosetteConf in 2025. Watch his talk to learn all about "pg_duckdb: Ducking awesome analytics in #PostgreSQL" (Livestream 2 on Wed Jun 12th @ 9:00am CEST (UTC+2))
Jelte Fennema-Nio (@jeltef) returns to #PosetteConf in 2025. Watch his talk to learn all about "pg_duckdb: Ducking awesome analytics in #PostgreSQL" (Livestream 2 on Wed Jun 12th @ 9:00am CEST (UTC+2)) 
Find out more: https://posetteconf.com/speakers/jelte-fennema-nio/

POSETTESpeaker: Jelte Fennema-Nio | POSETTE: An Event for Postgres 2025Jelte Fennema-Nio, Software Engineer @ MotherDuck, is a speaker for POSETTE: An Event for Postgres 2024. Jelte’s talk is titled “pg_duckdb: Ducking awesome analytics in Postgres”.



I should have looked at #DuckDB before, but with the built-in UI with notebooks (https://duckdb.org/2025/03/12/duckdb-ui.html) it feels really slick.
So note to self: refresh your #SQL !

DuckDB · The DuckDB Local UIThe DuckDB team and MotherDuck are excited to announce the release of a local UI for DuckDB shipped as part of the ui extension.

Show HN: GizmoSQL – Run DuckDB as a Server with Arrow Flight SQL
https://github.com/gizmodata/gizmosql-public/blob/main/README.md

GitHubgizmosql-public/README.md at main · gizmodata/gizmosql-publicGizmoSQL Public repo - used for README purposes and to make artifacts available for public download - gizmodata/gizmosql-public


Very nice! #duckdb has a web ui extension now. I don't always have gigantic queries I'm typing by hand. But when I do, this is going to be so useful to experiment with. 
https://duckdb.org/2025/03/12/duckdb-ui.html
DuckDB · The DuckDB Local UIThe DuckDB team and MotherDuck are excited to announce the release of a local UI for DuckDB shipped as part of the ui extension.